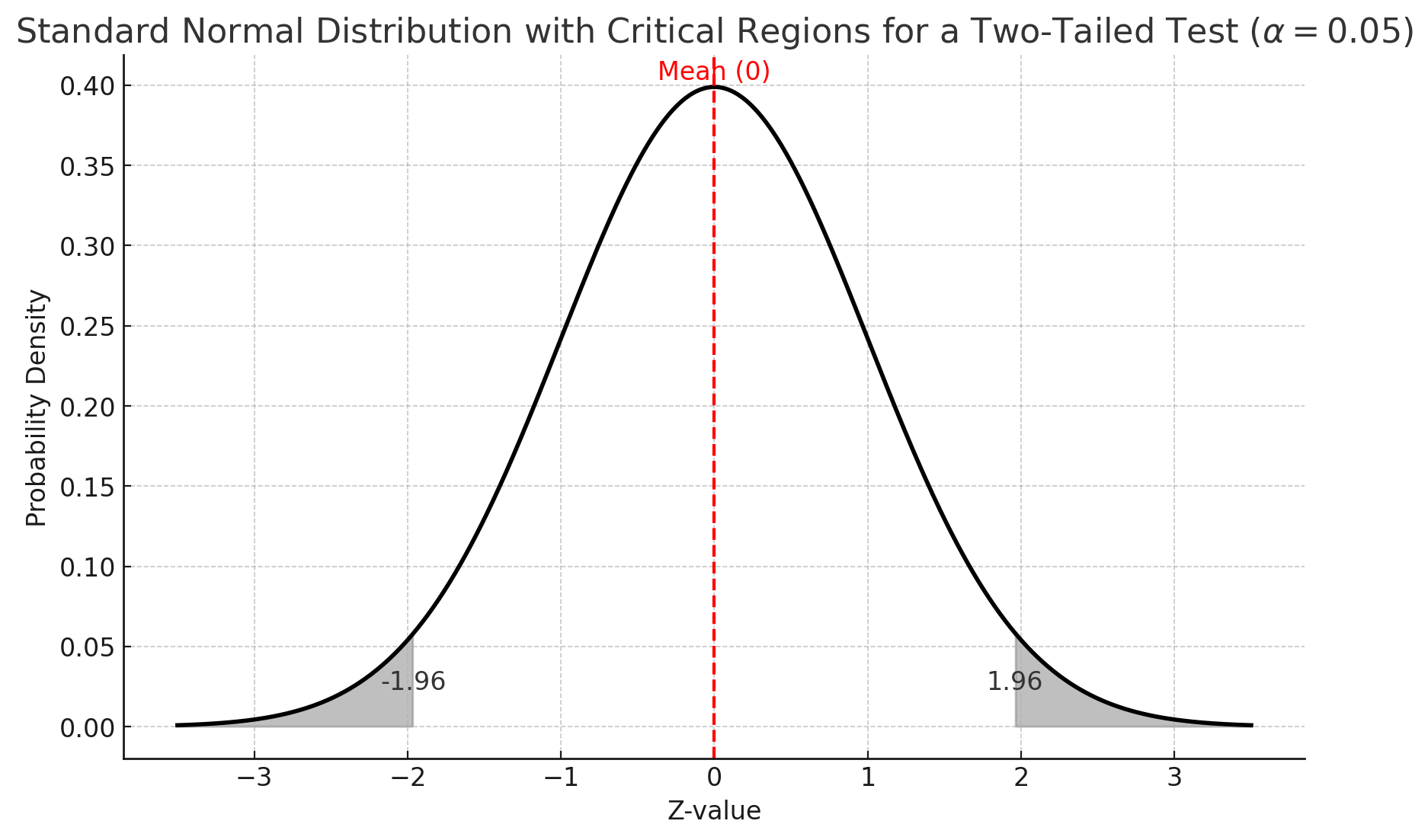
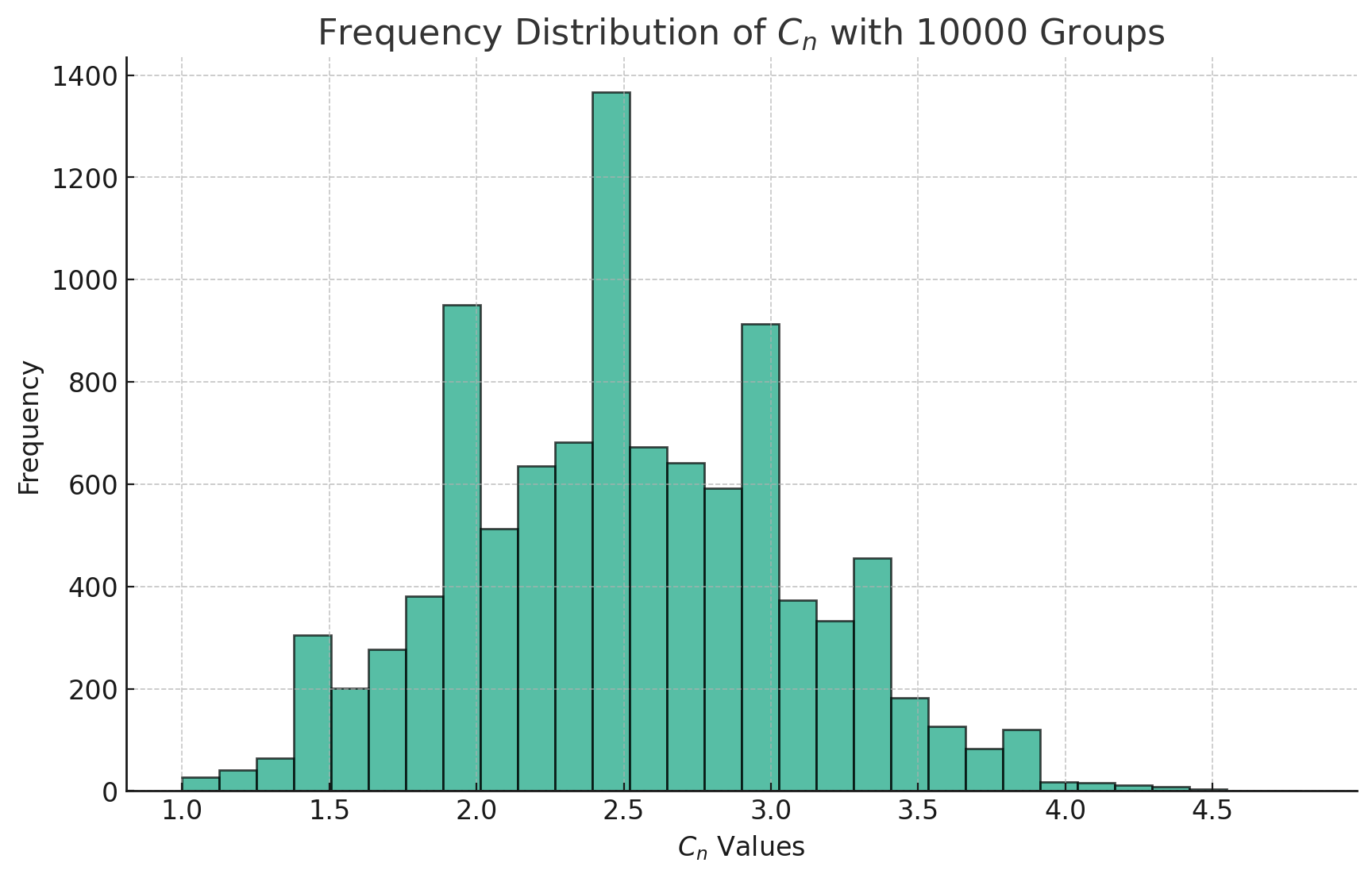
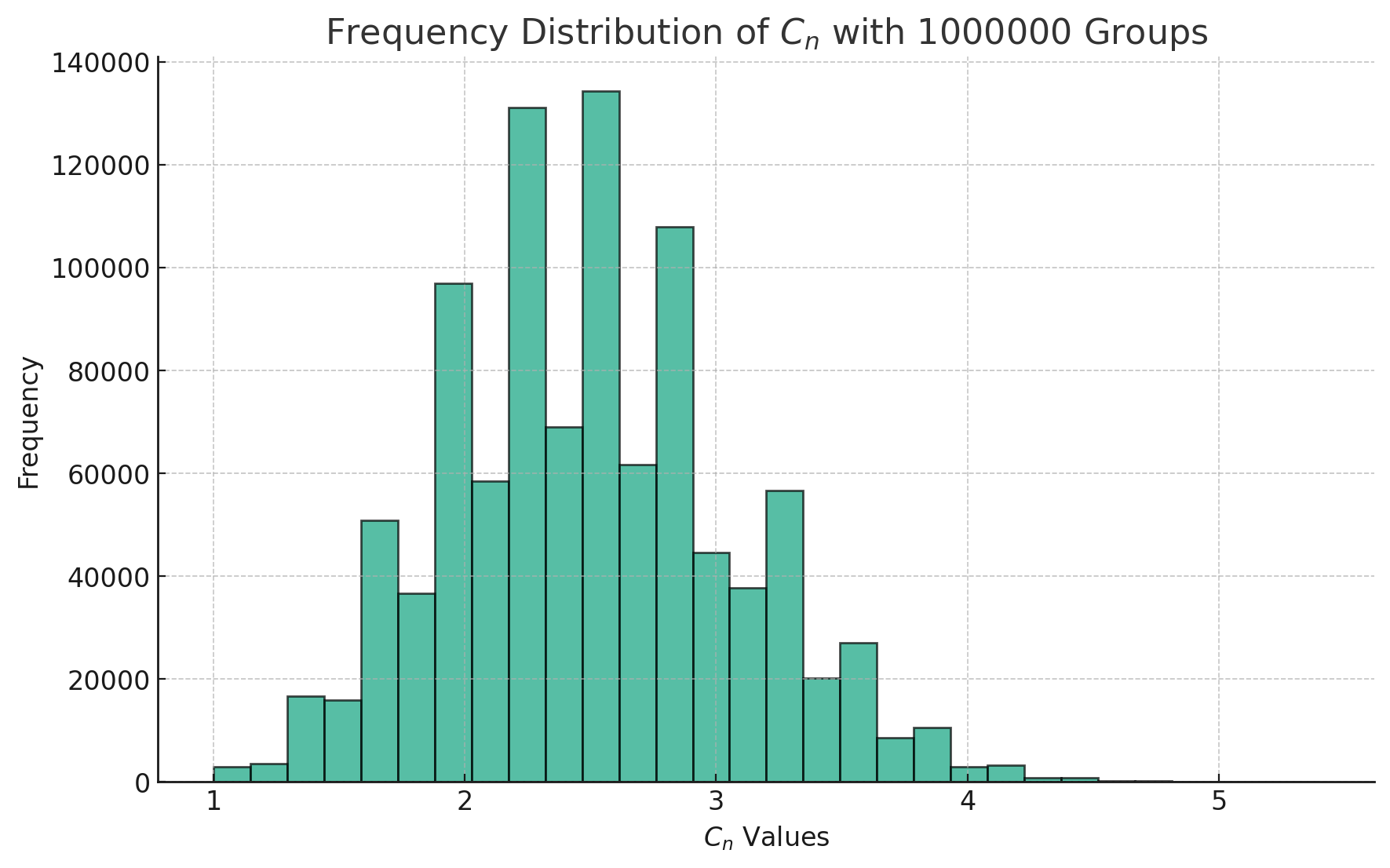
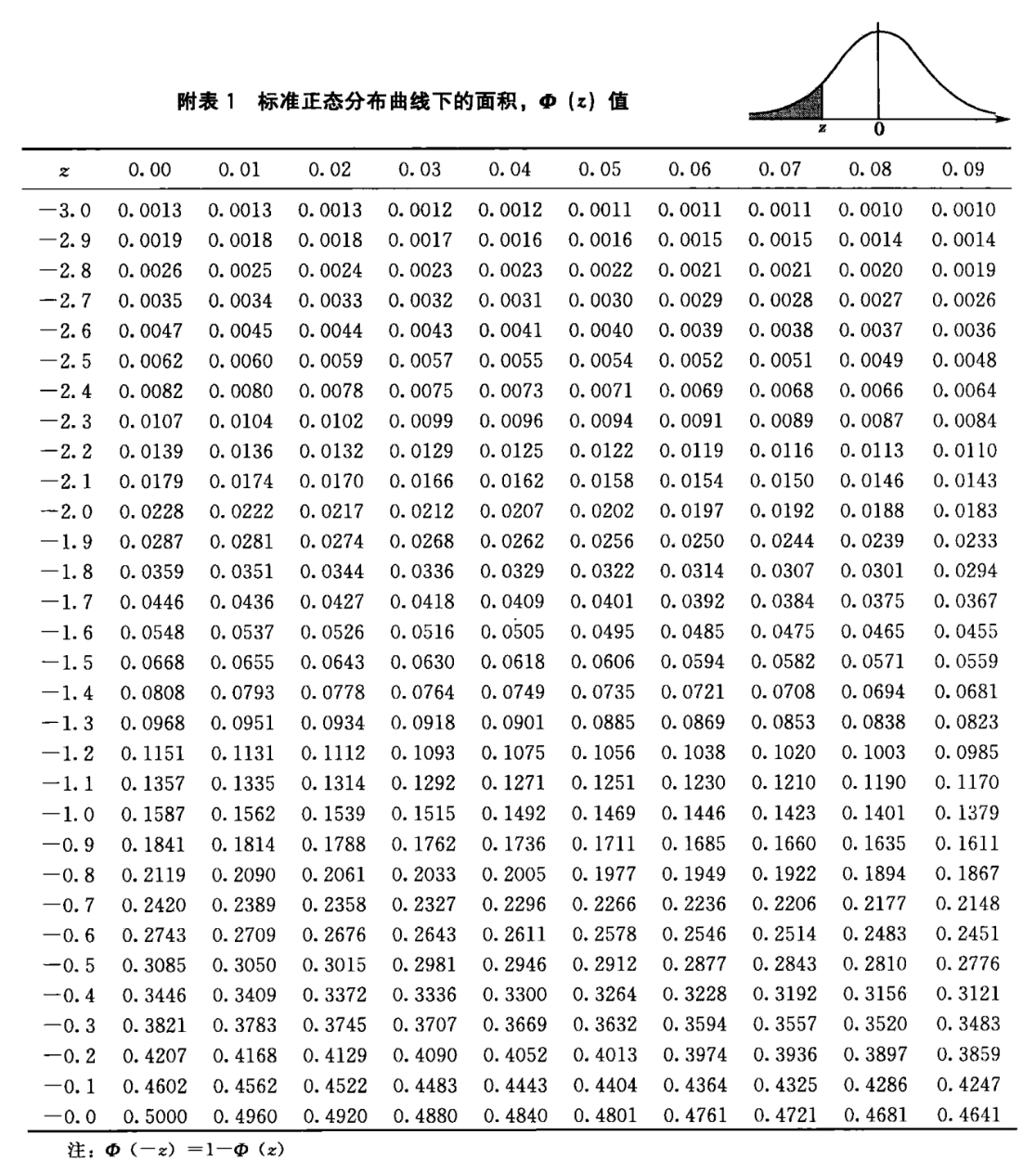
graph TD
A[定义问题] --> B[收集数据]
B --> C{数据类型}
C -->|分类数据| D[选择卡方检验]
D -->|一个变量| E[卡方拟合度检验]
D -->|两个变量| F[卡方独立性检验]
D -->|比较多个群体| G[卡方同质性检验]
E --> H[构建列联表]
F --> H
G --> H
H --> I[计算期望频数]
I --> J[计算卡方统计量]
J --> K[确定显著性水平]
K --> L[查找临界值或计算P值]
L --> M{P值 |是| N[拒绝零假设]
M -->|否| O[接受零假设]
N --> P[报告结果]
O --> P
flowchart TD
A[开始] --> B{研究设计}
B --> C{单个分类变量 与理论分布比较?}
C -->|是| D[卡方拟合优度检验]
C -->|否| E{比较不同群体 在同一变量上的分布?}
E -->|是| F[卡方同质性检验]
E -->|否| G{分析两个变量 之间的关系?}
G -->|是| H[卡方独立性检验]
G -->|否| I{成对或重复测量 的数据?}
I -->|是| J[配对卡方检验 如麦克尼马检验]
I -->|否| K[考虑其他统计方法]
D --> L{例子: 色子是否公平?}
F --> M{例子: 不同地区对产品偏好}
H --> N{例子: 性别与购物偏好}
J --> O{例子: 治疗前后健康状况改变}
flowchart TD
A[开始] --> B{数据和设计类型}
B -->|单一样本与理论分布比较| C[卡方拟合优度检验]
B -->|两个或多个分类变量之间关系| D[卡方独立性检验]
B -->|多个独立样本间比较| E[卡方同质性检验]
B -->|成对或重复测量数据| F[配对卡方检验\麦克尼马检验]
C --> G["例子: 检验色子是否公平"]
D --> H["例子: 吸烟是否与肺病独立"]
E --> I["例子: 不同学校学生对科学课程兴趣的比较"]
F --> J["例子: 新减肥药前后体重变化的比较"]
graph TD
A[卡方分析类型] --> B[卡方拟合优度检验]
A --> C[卡方独立性检验]
A --> D[卡方同质性检验]
B --> E[自由度计算:df = 类别数 - 1]
C --> F[自由度计算:df = 行数-1 * 列数-1]
D --> F
E --> G[举例: 单个变量的理论与观察分布比较]
F --> H[举例: 两个变量间的独立性分析]
F --> I[举例: 不同群体间同一分类变量的分布比较]
flowchart TB
A[开始] --> B{方差分析\nANOVA/MANOVA}
B --> C{检验显著性}
C -->|否| D[分析结束]
C -->|是| E[事后检验]
E -->|SNK| F[Student-Newman-Keuls]
E -->|Dunnett| G[Dunnett's Test]
E -->|Bonferroni| H[Bonferroni Correction]
B --> I{检验交互作用}
I -->|是| J[进一步探究\n交互作用]
I -->|否| E
F --> K[效应量计算]
G --> K
H --> K
J -->|进入事后检验| E
K --> L[假设检验之后的分析\n如线性回归、ANCOVA等]
L --> M[分析结束]
classDef startend fill:#f9f,stroke:#333,stroke-width:4px;
classDef process fill:#bbf,stroke:#333,stroke-width:2px;
classDef decision fill:#fbf,stroke:#f66,stroke-width:2px;
class A,B,M startend;
class C,I decision;
class E,F,G,H,J,K,L process;
flowchart TB
A[开始] --> B{进行ANOVA测试}
B --> C{ANOVA结果显著?}
C -->|否| D[无需进一步比较]
C -->|是| E[选择多重比较方法]
E --> F{比较的目的}
F --> G[比较多个实验组与一个控制组]
F --> H[比较特定几个组]
F --> I[全面比较所有组间差异]
G --> J[Dunnett法]
H --> K[Bonferroni校正]
I --> L[SNK方法]
J --> M[执行Dunnett比较]
K --> N[执行Bonferroni校正的两两比较]
L --> O[执行SNK步骤比较]
M --> P[得到比较结果]
N --> P
O --> P
graph TD
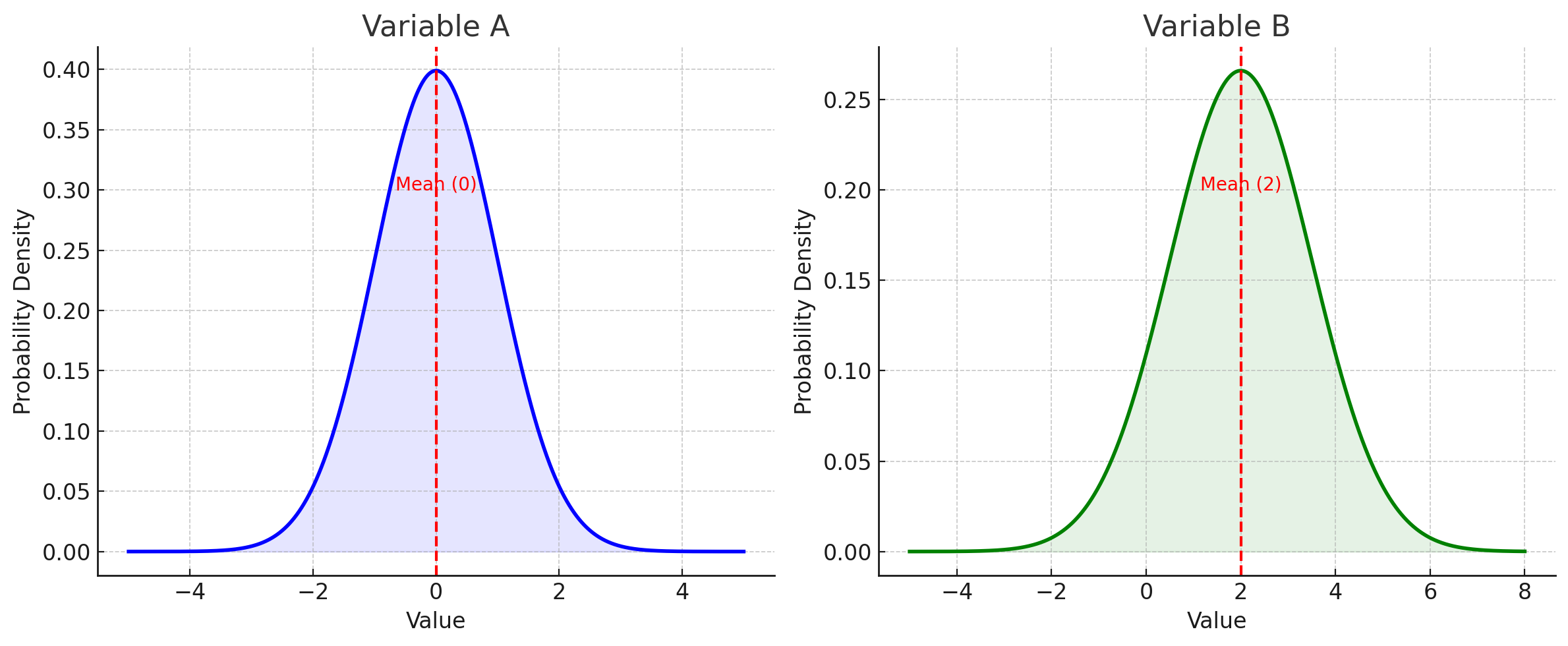
0[(随机样本 来自正态分布总体 比较均数时)]:::highlight
0 -->|建立假设| A{检验数据正态性}
A -->|正态分布| B{检验方差齐性}
A -->|非正态分布| F[使用非参数检验]
B -->|数据量相似| C[选择方差齐性检验]
C -->|Levene检验| D[当数据偏离正态分布]
C -->|Bartlett检验| E[当数据严格正态]
C -->|F检验| G[样本量大且满足正态]
B -->|数据量不相似| H[推荐Levene检验]
D --> I{方差是否齐性}
E --> I
G --> I
H --> I
I -->|是| J[选择Student's t检验或Welch's t检验]
I -->|否| K[使用Welch's t检验]
J --> L[独立样本T检验或配对样本T检验]
K --> M[独立样本Welch's T检验]
L --> N(计算t值)
M --> N
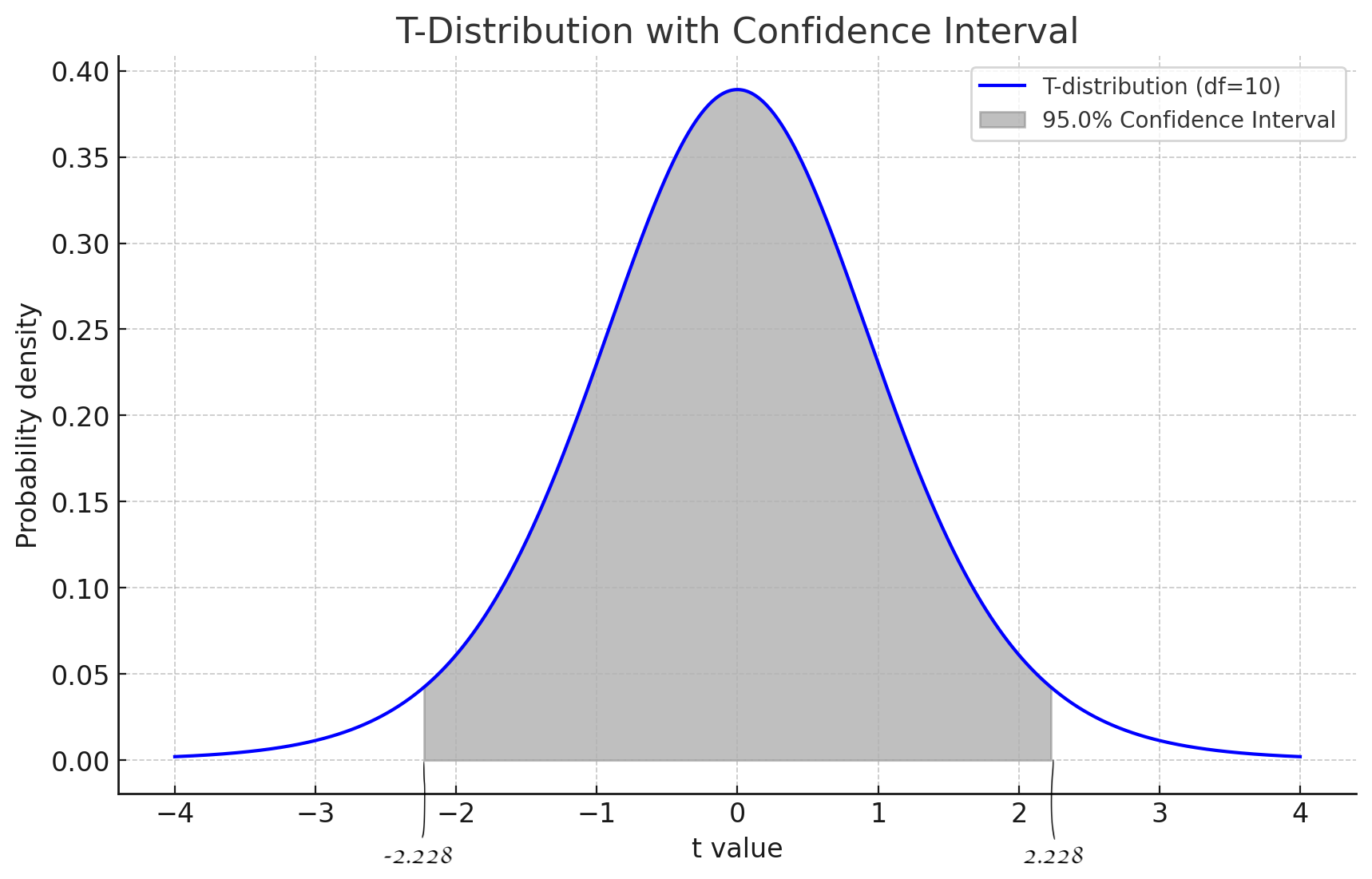
N --> O(确定显著性水平 α)
O --> P(查找t分布表以确定临界t值)
P --> Q{比较计算得到的t值与临界t值}
Q -->|计算的t值 大于 临界t值| R(拒绝零假设,接受备择假设,差异显著)
Q -->|计算的t值 小于等于 临界t值| S(不能拒绝零假设,差异不显著)
classDef highlight fill:#ffff00,stroke:#333,stroke-width:2px;
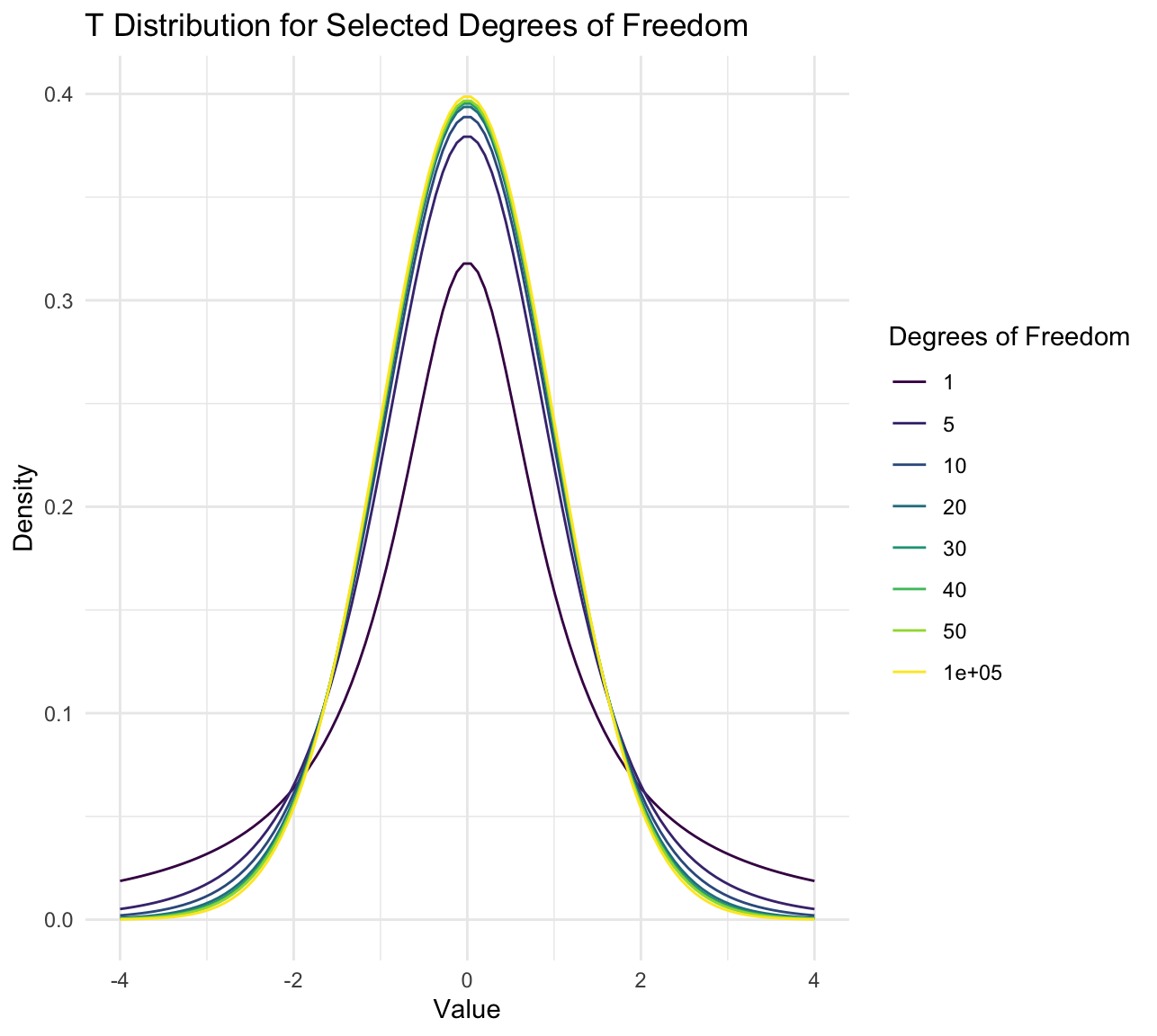
# 生成选定自由度的t分布数据 for(df in dfs){ x <- seq(-4,4, length.out =100)# 生成值序列 density <- dt(x, df)# 计算密度 df_t_selected <- rbind(df_t_selected, data.frame(x, density, df = as.factor(df)))# 添加到数据框 }
# 使用ggplot2绘图 ggplot(df_t_selected, aes(x = x, y = density, color = df))+ geom_line()+# 绘制线条 labs(title ="T Distribution for Selected Degrees of Freedom", x ="Value", y ="Density", color ="Degrees of Freedom")+ theme_minimal()+ scale_color_viridis_d()# 使用viridis颜色方案增强可视化
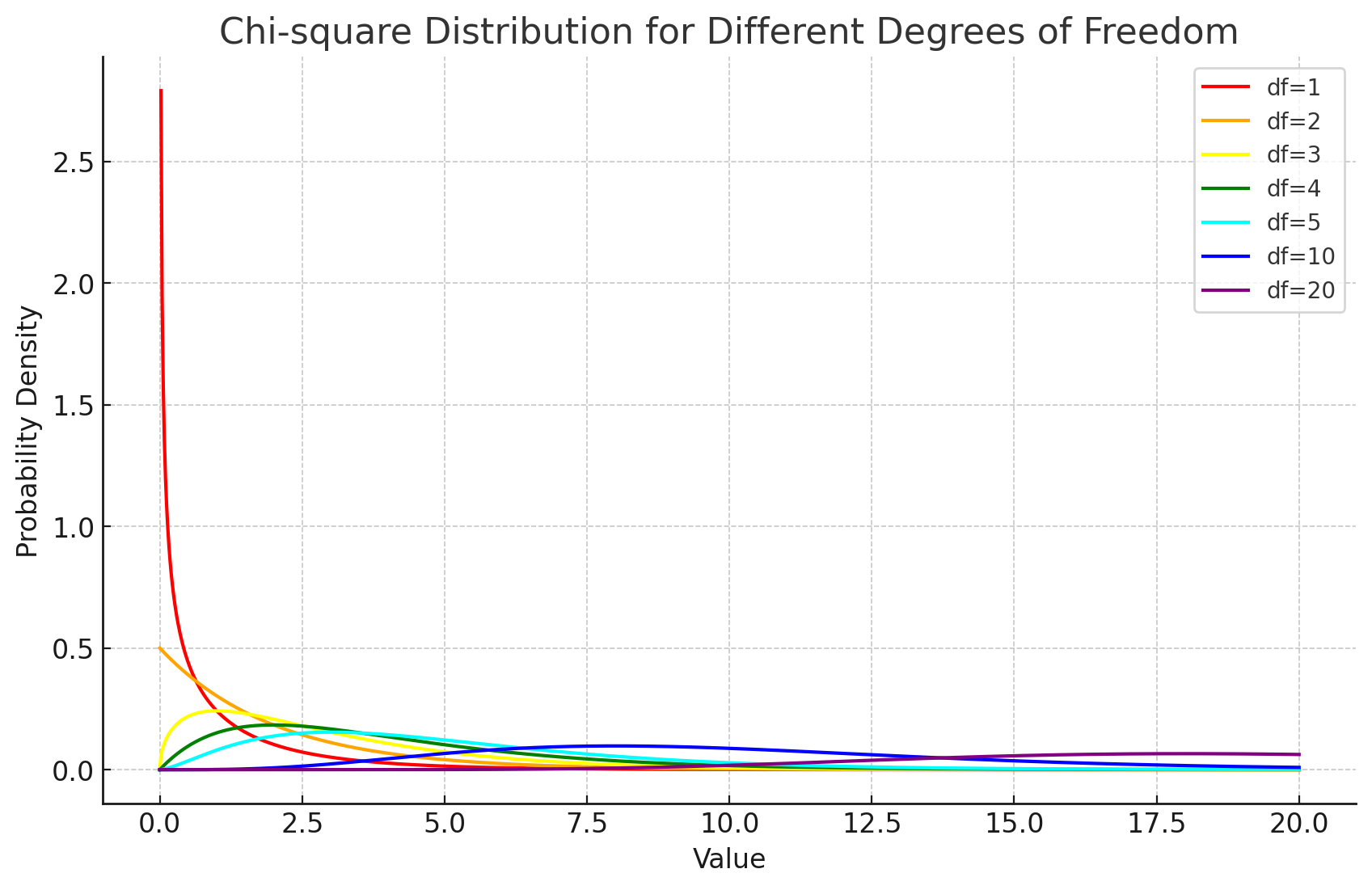
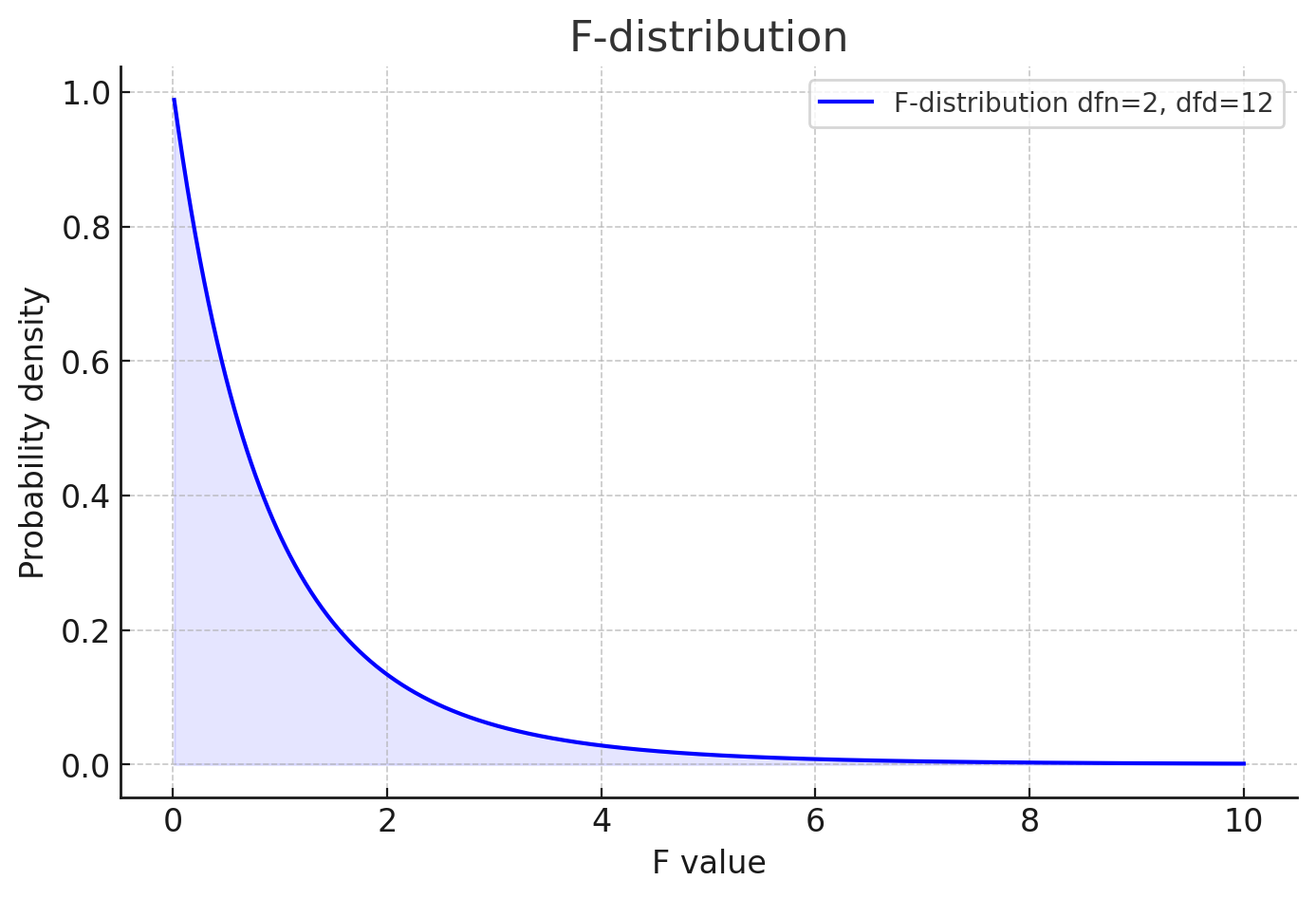


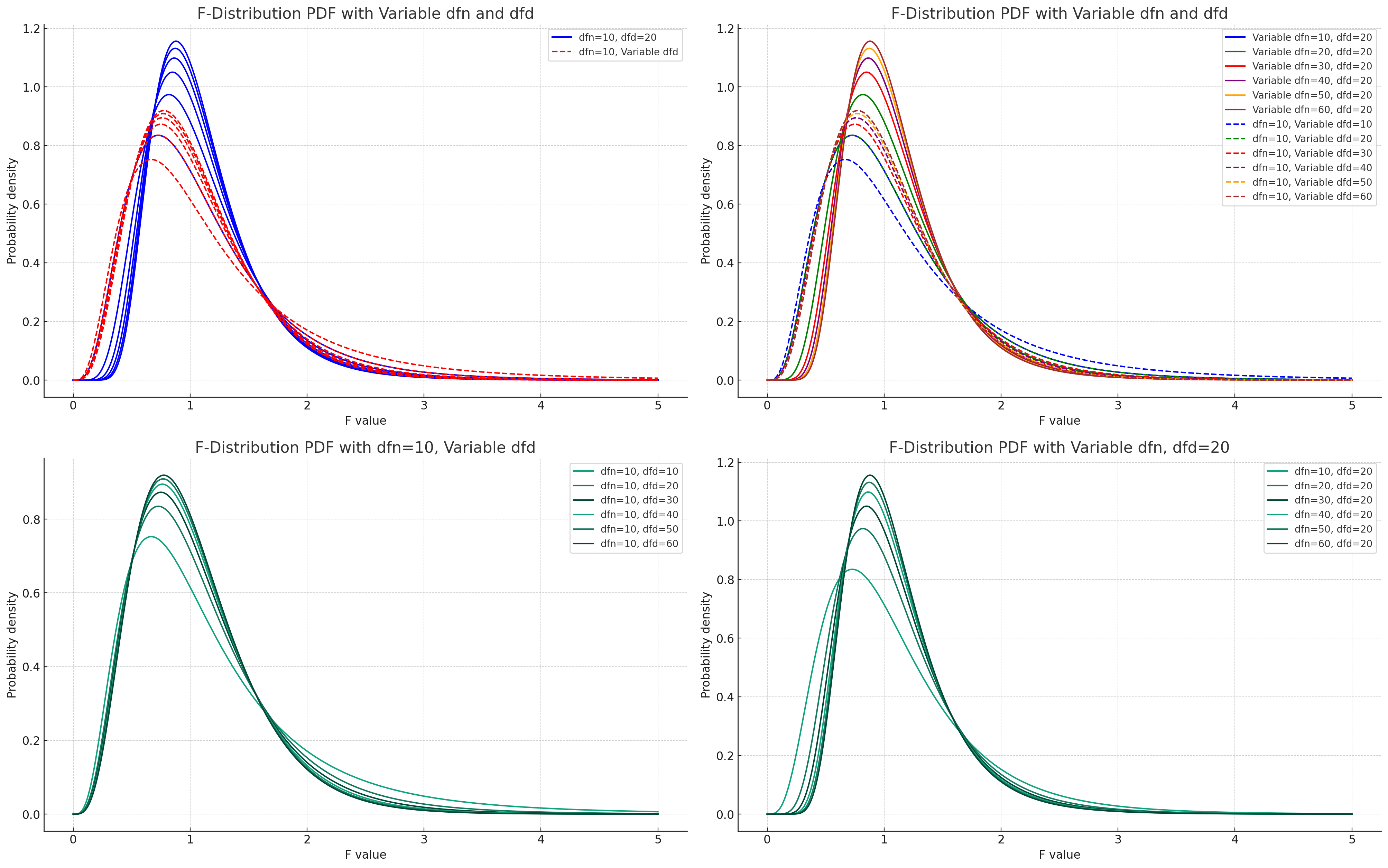 根据参数为(自由度、分母)的F图像,得出p值
根据参数为(自由度、分母)的F图像,得出p值